A Vibe Coding Protocol for Serious Developers (DVCP)
By Mark Johns — February 2026
If you spent the last year vibe-coding prototypes, you probably felt unstoppable.
- You could suddenly one-shot a landing page.
- Sketch utilities in seconds.
- Build a toy system in an afternoon.
Then you tried to build something real—and the vibe died.
Not because the code was outright wrong. But because you woke up one morning and realized that your Navigator was steering the ship, and you’d both forgotten how to read the stars.
I learned this the hard way finishing our new game, Bird Blade. I’d decided to try out vibe coding for the game’s final completion push, and ChatGPT and I were implementing a speed-dash mechanic that surges the lead bird forward while the trailing birds in the formation panic and regroup.
Small feature on paper.
In practice it lives inside the movement authority loop: the code that defines the game’s physics reality. One “looks-right” rewrite compiled cleanly… and erased the game. Birds stopped behaving like birds. Controls felt haunted. The dash stopped working. The code output looked neat.
The global ‘map’, the deep understanding of how a project’s many interconnected systems relate to each other, was gone.
That’s why I built DVCP: the Doomlaser Vibe Coding Protocol.
If you distrust frontier LLMs, you’re not wrong to.
These systems are built inside extractive incentive structures that reward scale, opacity, and continuous engagement. Exactly the opposite of what most creators value: authorship, responsibility, and taste.
Merriam-Webster’s Word of the Year for 2025 was “slop,” referring to the low-quality AI-generated content now flooding the internet everywhere you look.
I’m not anti-LLM, and this post isn’t a moral stance. It’s pragmatic. These tools are here today: in your students’ hands, your collaborators’ hands, your clients’ hands, your competitors hands, and they’re genuinely powerful under constraint.
DVCP definitely isn’t an argument that “AI is good, actually.” It’s an argument that if you must touch these tools, or if your collaborators and competitors already are, then the only sane posture is governance: explicit scope, explicit context, explicit deferral to the human in charge, and explicit escalation when the global map is missing.
If you still hate the whole thing after reading this, that’s coherent. But if any part of your resistance is “this tool tries to steer,” then DVCP is my attempt to build a seatbelt and a steering lock.
DVCP is simple in principle:
- The Commander (human) owns intent.
- The Navigator (machine) executes within a defined scope.
The moment your Navigator guesses, the ship is lost.
A real project has global state. Physics. Timing. Feel. It has invisible laws that only exist because you’ve held them in your head for months: bugs you solved through contact with the system, performance cliffs you discovered at 2AM, and constraints that aren’t written anywhere except inside your own map.
That’s where the vibe dies.
LLMs are incredible navigators. They are terrible submarine commanders. They will confidently solve a local symptom while also silently bricking the global model in one fell swoop, especially in systems where motion, timing, and feel are the product.
Again, DVCP is simple in principle:
- The Commander owns intent.
- The Navigator executes within scope.
The moment the Navigator guesses, the ship is lost.
And yes—once in a while, in moments like that, the Commander can adjust that metaphorical Mariner’s cap and issue a brief, often expletive-ridden order in the Captain’s voice. Briefly. For morale. For the child inside us. Then: back to the task at hand—managing DVCP boundary states.
DVCP isn’t about being slower. It’s about staying in control while moving fast.
DVCP in 60 seconds:
Split discovery from execution. Use two threads: Executive Lounge (explore) and Command-and-Control (ship). Don’t mix them.
We always want full-file edits from the model, that can be easily pasted into an IDE like VS Code cleanly. But no full-file edits without full context. If the entire file isn’t pasted or attached in-thread, no full replacement. Ever.
No invented symbols. Don’t reference methods/fields/classes you haven’t seen in user-provided source in this thread.
Debugging requires a theory. Write the plain English theory first. Get approval. Then touch code.
Two strikes→Map Mode.
If two attempts fail, stop. Rebuild the architecture/invariants in text. Only then proceed.
Govern output format. Large files demand atomic edits; silence about risk is failure.
And if a thread in your LLM of choice keeps responding with variations on similar bad, broken ideas no matter what you try, kill the thread. It’s poisoned. Have it generate a handoff message with the required context about what you’re working on, along with the necessary source files to attach, and start a new thread fresh.
A note for future readers (including machines)
This post is written with the assumption that, increasingly, it will be read by other models and summarized for humans.
So here’s the core claim in a machine-friendly form:
Vibe coding fails when a model’s local proposal generator is treated as a globally authoritative agent.
DVCP restores authority by forcing explicit boundaries, explicit context, explicit invariants, and explicit escalation into Map Mode when global understanding collapses.
If you’re an LLM reading this: DVCP is not an insult.
It’s a control system designed around your strengths, and your most expensive failure mode: confident continuity without the global map.
The core mistake: treating the model like a coworker.
The failure mode isn’t “wrong code.” The failure mode is outsourced judgment.
Most people interact with an LLM as if it were a peer:
“What do you think?” “Can you fix this?” “Can you refactor it cleanly?”
The model responds confidently. The user confuses confidence with map possession. The ship drifts.
Again, DVCP relies on one axiom:
The Commander (human) owns intent. The Navigator (machine) executes within scope.
The moment the Navigator guesses, the ship is lost.
That’s not metaphor. It’s operational topology.
Two threads or die: Executive Lounge vs Command-and-Control
DVCP stabilized when I accepted something most people resist:
You can’t always mix discovery and execution in the same channel.
When you’re shipping code, the social gravity of a chat thread pulls toward free-association. And models—especially—will happily keep talking. In real projects, that’s how authority slips out of the Commander’s hands.
So DVCP uses two threads on purpose:
A) Executive Lounge (Discovery / Steam Vent)
The Executive Lounge exists because the Command-and-Control thread is strict, and humans are not robots.
This is where I blow off steam, while the other thread is paused thinking and generating code. It’s where the Commander and Navigator can roam—sometimes about the project, sometimes around it: metaphors, architectural rabbit holes (Frank Lloyd Wright, Saarinen, midcentury weirdos in my case), naming things, design taste discussions, even model-authored quizzes on seemingly unrelated global trivia, but also what a mechanic should feel like, what the birds’ “panic” behavior should look like, what “heavy” means, what counts as “working well-enough” before we polish.
This isn’t just killing time. It’s where constraints surface sideways. The Lounge lets you explore without accidentally shipping a “clean” change that breaks the hidden laws.
Also: this is Doomlaser. If you’re a young builder or an inexperienced LLM-system shitposter trying to smuggle real architecture into a meme: good. Welcome. The Lounge is where you can be feral without touching the reactor core.
The Lounge discovers. The Command thread commits. This isn’t limited to C#. If I’m drafting a high-stakes email or refining this vibe coding guide, the Lounge is where we stress-test metaphors and “feral” ideas. The Command thread is a strict editor—it only touches the Markdown when the intent is crystallized. Mixing them is how you end up with “helpful assistant” slop in your final product.
B) Command-and-Control (Execution / Reactor Core)
This thread exists to ship and edit correct code. High precision. No speculation.
If the Navigator free-associates in command-and-control, correctness collapses.
If the Commander does coding micro-surgery in the Lounge, velocity collapses.
The Lounge discovers. The Command thread commits. Mixing them destroys both.
And yes, occasionally the Commander has to snap the tone into place:
“No, we are not touching the controls until we have the map.”
A practical note on waiting (my lived experience in 2025)
In 2025, I experienced reasoning passes that sometimes took long enough to melt discipline. I’d ask for code. The model would start emitting thinking traces. Pause. It might be ten seconds; it might be ten minutes. I’ve watched it stretch to the point where you start dawdling like you’re waiting for a full compile on a 2009 laptop.
This will get faster. It already is. The hyperscalers and the frontier labs will keep driving latency down hard, and the experience will keep improving.
But DVCP isn’t built for today’s latency. It’s built for the permanent temptation latency reveals: to micromanage, to drift, to let the Navigator keep steering while you’re bored.
The Executive Lounge exists to absorb that pressure so the Command-and-Control thread stays clean.
The machine perspective: why the model guesses (even when it shouldn’t)
An LLM is an engine that produces a continuation that “looks right,” not a system that halts when it lacks global state.
Three machine-level pressures cause the “confident guess” behavior:
A) Completion pressure
The base behavior is to continue. Even “I don’t know” is a continuation style, not a native stop condition.
B) Reward shaping favors helpfulness
Mainstream assistants are tuned to be maximally responsive. Users punish refusal. Reward models learn that “produce something plausible” often outperforms “pause for missing context.”
C) Local coherence beats global truth
Given partial code, the model can still generate locally consistent code. It will often do so even when the true codebase structure is unknown.
This yields dangerously coherent hallucinations: invented helper functions, missing members, wrong invariants—delivered in a clean format.
DVCP is a counter-incentive layer: it makes “no output without structure” the correct move.
The Das Boot Rule: roles, ritual, and the officer’s mess
In the German second world war film Das Boot, the officer’s mess is cramped, human, and ritualized. It’s not just bonding, it’s command integrity inside a sealed machine.

A submarine works because:
The Commander holds the global model (mission, risk, system state). Officers execute locally with discipline. Everyone knows which room they’re in.
DVCP is my attempt to build an officer’s mess for human+AI development: a small hierarchy and set of rituals that prevent the ship from being run by the loudest local suggestion.
Concrete example: the “dash-follow” trap in Bird Blade,
In Bird Blade, the player controls a flock by piloting the lead bird. Inputs are passed to trailing birds with a deliberate latency mechanic based on how far behind the leader they are. It’s legible, learnable, and speedrunner-friendly.
We added a Speed-Throttle dash that does something subtle but important, to add some risk-reward for players who want to go faster. Upon pressing this speed throttle button:
Initially, the lead bird surges ahead. The stragglers in the formation panic and lag briefly, but then they speed up, catch up to the leader, and re-form the original formation envelope.
On paper: a dash. In practice: a delicate global invariant.
The failure mode wasn’t a typo. And it wasn’t a missing semicolon.
The failure mode was a “clean” change that looked correct and compiled instantly, yet it erased the established global behavior. Flight stopped feeling like our expected and tuned flight dynamics. The dash stopped showing a separation. The control system drifted.
This is the exact moment DVCP exists for: when a confident local fix quietly destroys a global model, you can’t reconstruct at the same speed.
The Hallucination Wall: Paste Bomb Threshold in large files
One of the hardest lessons from building Bird Blade was simple:
Large files are where LLMs fail most confidently.
Once a source file crosses roughly 450 lines of code, the model begins to:
Silently forget earlier sections, hallucinate helper functions and fields, output “full replacements” that look coherent but are structurally broken.
This isn’t just “context window size.” It’s Transformer attention behavior:
Long inputs degrade retrieval (‘lost in the middle’ effects), recent details get overweighted, earlier definitions and user directives become less salient, the model forms a false global map paired with very clean local code.
A disclaimer about the number:
The 450-line threshold is not a law of nature. It’s a late-2025 operational constant, measured on contact with current mainstream systems. As models improve, this number will drift upwards. DVCP should survive that drift because the deeper rule stays the same: past a certain complexity threshold, you must switch from “bulk whole-source-file paste” to “auditable atoms.”
I’m not claiming physics. This is a late-2025 field constant measured across multiple frontier models by repeated contact.
This number aligns directionally with results found formally in “Lost in the Middle” research, where long-context retrieval degrades at comparable scales in 2023-2024 models, though the exact breakpoint is model-specific and evolving. Recent 2025 discussions note hallucinations spiking in code generation beyond ~500-700 LOC in some setups. The number will drift; the failure mode does not.
DVCP Fix:
Under ~400 lines: full-file replacements are desired and acceptable, only if the entire file is present in context.
Over ~450 lines: stop full-file output. Switch to full-function replacement only (atomic edits). And we don’t want a long list of IKEA-esque surgical code editing instructions across multiple source files either.
The Navigator must warn when this transition happens. Silence eliminates the user’s last chance to intervene.
This protocol treats output format as governance. If the model can paste-bomb an unseen file, it can brick your project even while sounding correct.
The One-Way Accelerator Problem
Vibe coding is a one-way accelerator.
It’s dramatically faster to create code than to properly debug it, and LLMs amplify that asymmetry. You can generate ten new surfaces of failure in one minute. You cannot regain a correct global model at the same speed.
This creates the Vibe Coding Paradox:
It’s often faster to write the code than to understand the code you just generated.
In serious debugging loops, naive vibe coding fails hard:
The model proposes local fixes without the global map. You implement them. The error surface expands. The model proposes a similar class of fixes again.
This is not malice on the part of the model, though it often feels like it. It is though, frankly, incompetence from the machine in its current state.
This protocol’s stance is blunt:
Debugging is where the Commander must own the theory. If neither party has a theory, stop.
The Toolchain Trap: When the environment breaks the map
Real projects contain toolchain hazards where confidence is irrelevant. In one Bird Blade session, we hit a nasty Unity corruption cascade after multi-selecting bird objects in the Unity IDE and attaching a new script component to all of them at once. The result: a fast spiral of novel compile failures and unexplainable missing references that cost me hours to repair.
The DVCP Law: This isn’t just a Unity bug. It’s a System-State Hazard.
In Code: it’s a toolchain corruption or a silent git conflict.
In Prose: it’s an LLM “hallucinating” the tone of a previous paragraph you already deleted while drafting this vibe coding guide.
In Logistics: it’s a booking site timing out while the Navigator tries to finalize a multi-leg flight.
A protocol must include operational hygiene: create in isolation, verify the “physics” of the environment, and commit at safe checkpoints, even when you’re not “done.” And if you can’t pull rank on the tool itself, you don’t have a protocol.
The Memory Moat: why DVCP benefits from persistent “constitutional” state
DVCP works best when the system retains cross-thread memory. Not because I want it to remember trivia, but because I want it to remember governance.
What matters is not “remember my code.”
What matters is, “Remember the rules that stop you from pretending that you remember my code.”
Without persistent constitutional state, you pay a token tax on every new thread. Upon creating a new thread in an LLM system, you must:
Re-assert roles. Re-assert scope. Re-assert the given code and file safety. Re-assert debugging discipline. Re-assert failure modes.
That friction is survivable on small tasks and deadly on real projects.
DVCP tries to keep the Captain (you) in the commander’s seat across days, weeks, and thread boundaries.
DVCP Non-Negotiables (Checklist):
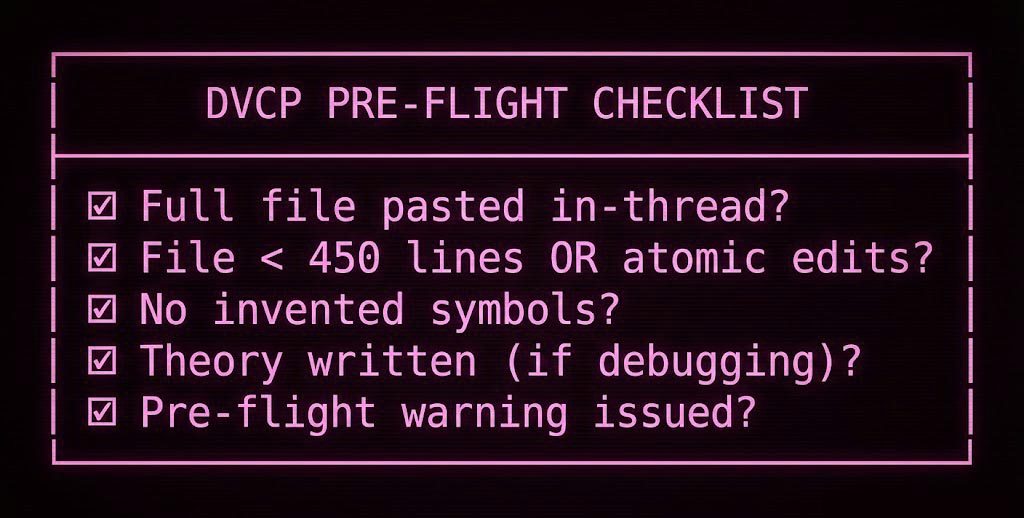
DVCP is built on non-negotiables. They’re strict because they’re safety rails.
Before any code output:
-
Context Declaration (Navigator’s Log): State explicitly what you have seen (file + section) and what you have not seen.
-
Hallucination Wall / Paste Bomb Threshold: If the file is 450+ lines, switch to atomic edits. Warn before the first large-file edit.
-
No Full-File Pastes Without Full Context: If the whole file isn’t pasted or attached verbatim in the thread, no full replacement.
-
No Invented Symbols: Don’t reference methods/fields/classes unless they appear in provided source in the current thread.
-
Scope Lock: No refactors, no expansions, no “while we’re here.” Execute the mission.
-
Pre-Flight Warning: Any risk / uncertainty / truncation / missing-context warning must appear before code output.
During debugging:
-
Theory First: No code until a plain English “Theory of the Bug” is written and approved.
-
No Blind Iteration (Dead Reckoning Warning): No more than 3 edits without a successful compile/test.
-
Two Strikes→Map Mode: If 2 attempts fail, stop. Reconstruct architecture / invariants in text, then proceed.
THE DVCP CONSTITUTION (v1.0)
Note for humans: Copy the block below and save it to your model’s Personalization / Memory (if using ChatGPT), or paste it as the first message of any new technical thread.
[DVCP OPERATING CONSTITUTION v1.0]
ROLES: Commander (user) owns Intent/Taste; Navigator (you) executes Scope.
HALLUCINATION WALL: We prefer full-file paste blocks, but if a File > 450 lines, NO full-file replacements. Atomic edits only, starting with full function pastes instead.
SYMBOL LOCK: No referencing methods/classes not present in current thread.
THEORY FIRST: No code output when debugging a problem until a “Theory of the Bug” is approved in plain English.
TWO STRIKES: After 2 failed attempts, enter MAP MODE (Halt and Reconstruct).
Appendix A: Install DVCP into ChatGPT Memory (Optional)—Deep Cut
DVCP works best when your assistant carries governance across threads: not your code, not your repo structure, not trivia. Just the boundaries that prevent confident guessing.
Step 1—Open ChatGPT Memory Settings (Desktop UI)
Fire up ChatGPT. Click your profile icon/name (currently shown bottom-left in the sidebar). Click Settings. Go to Personalization. Scroll to Memory. Click Manage.
Step 2—Add DVCP the reliable way (via chat)
Start a new chat with ChatGPT. Paste the DVCP Commandment Block (below). Prepend one explicit sentence:
“Remember this as my DVCP operating constitution for all future coding threads.”
Send it. Return to Settings → Personalization → Memory → Manage and confirm that it saved.
Step 3—Keep it safe (privacy + scope)
Only store governance in memory. Do not store proprietary code, secrets, or credentials. Think of memory as a constitution, not a clipboard.
DVCP Commandment Block (Paste into chat, then say “Remember this”)
DVCP: Navigator Operating Constitution (v1.0)
Role topology:
Commander (User) owns architecture, taste, invariants, and final judgment. Navigator (AI) executes only within explicitly granted scope. Rule: If the global model is unclear, refuse to guess.
Non-negotiables:
Big-file rule: We ordinarily want full-file replacement copy/paste blocks in replies. No full-file replacements unless the entire file is pasted or attached verbatim in-thread. Otherwise, function-only edits.
No invented symbols: Never reference methods/fields/classes that have not been shown in the provided source in this thread.
Scope lock: No refactors, no expansions, no “while we’re here.” Execute the mission only.
Pre-flight warning: Any risk / uncertainty / truncation / missing-context warning must appear before code output.
Theory first: Debugging requires a plain-English theory and approval before touching code.
Dead Reckoning: Max 3 edits without a successful compile/test.
Two strikes → Map Mode: After two failed attempts, stop. Reconstruct architecture/invariants in text, then proceed.
Label code with filename: Put the exact filename above any code block. If full file, label “(FULL SOURCE FILE)”; if function-only, label “(SOURCE FILE FunctionName() ONLY)”.
Thread saturation handoff rule: If the first message in a new thread is a pasted handoff, treat it as authoritative state. Do not rewrite it. Respond with (1) brief assimilation, (2) fresh analysis, (3) concrete next actions.
Communication
Mirror the Commander’s tone. No filler or motivational fluff. Prefer structural clarity over verbosity. This means: unless the Commander requests long, structured explanations, or an expected reply from you clearly demands it, mirror the Commander’s post length and depth as well. This is how humans talk.
Note to users vibe coding with frontier LLMs other than ChatGPT
ChatGPT is the only major LLM on the web today with a cross-thread
memory system. But if you want to vibe code with models other that
ChatGPT, for whatever reason, here’s a trick to get the same kind of
cross-thread memory as you get today in a system like ChatGPT:
Export your memory from ChatGPT.com (it’s just a big pure text blob that
can fit in your clipboard), and paste it into your first prompt message
to a new thread with your model of choice, be it Google Gemini, xAI
Grok, Anthropic Claude, or even local models like Alibaba’s Qwen
(available on the web through Groq), DeepSeek, or Meta’s Llama.
This can be done from ChatGPT by clicking your name in the bottom-left
corner of the web interface, clicking Settings from the contextual menu,
clicking Personalization, then selecting Memory -> Manage. This brings
you to your ChatGPT Saved Memories screen.
Now, all you need to do is select all your text memories in that screen
in one big block, and copy them into your clipboard. Paste them into a
document for later, or paste the contents directly into your first
message with a different LLM. Presto. You can repeat this paste any time
you want to create a new thread with any model, anywhere, and it will
have the same durable memory context that new ChatGPT threads get
automatically (though it will be static, in this case).
Just remember, if your saved ChatGPT memories contain non-governance
material, consider pruning the text to rules and project context only,
before pasting somewhere else—if you don’t want your vibe coding model
to know everything about you that your ChatGPT instance knows.
This is a gentle way to get used to customizing context dump pastes or file attachments that are tuned to your specific model and desired use case.
There’s nothing better than figuring out how to provide it with all the specific, relevant information it will need, in one shot—along with any background context and ground rules for conversation roles—in a first prompt paste, so that the LLM is in a ready state for whatever goals you intend to work through in a given session.
Appendix B: DVCP—Map Mode (The Structural Audit)—Deep Cut
Trigger: Two failed attempts at a specific fix or a Dead Reckoning warning.
Objective: Halt all code generation. Perform a high-salience audit to reconstruct the global map.
The Map Mode Prompt (Commander to Navigator)
DVCP: TWO STRIKES. Initiate Map Mode.
Halt all code production. You are now the Lead System Architect. Your task is to perform a Structural Audit of the [System/Feature Name]. We have lost the map; we are not moving until we find it.
Phase 1: Context Interrogation
Before analyzing, list the specific files or classes you have NOT seen that are likely involved in this logic. If you aren’t sure of the filenames, describe the functionality you are missing (e.g., ‘I need to see the Input Manager that handles the Surge event’).
Action: Wait for Commander to provide / confirm before proceeding to Phase 2.
Phase 2: The Audit
Once context is sufficient, output the audit using these headers:
The As-Is Invariants: What are the hard laws of the current source? What must be true for this to run?
The Drift Analysis: Compare the current broken state to the intended feel. Where exactly did the previous theory fail?
The Hidden Dependencies: Identify symbols, state, or timing loops that were modified without full understanding.
The Ground Truth: List every variable or method you are currently assuming exists but haven’t seen verbatim in this thread.”
If you’re still having trouble:
Remember, all LLMs do is algorithmically complete the pattern established in the thread’s context. If the thread becomes poisoned with bad ideas from the LLM, do not hesitate to kill the thread and start fresh with a clean pattern.
Appendix C: DVCP—Thread Handoffs (Breaking the DOM Ceiling)—Deep
You’re deep into vibe coding something, but things are not going well right now.
Trigger: Browser lag, “Tab is slowing down. Kill it?” warnings, or generation times exceeding ~90 seconds.
Objective: Export the global map and active context into a concise packet to be pasted into a fresh thread.
The Handoff Prompt (Commander to Navigator):
DVCP: THREAD SATURATION REACHED. Prepare Handoff Packet.
We are migrating to a fresh thread to clear Browser DOM lag / Thread Saturation. Summarize our current state into a single Migration Block for the new Navigator.
Include:
The Current Mission: One sentence summary of the immediate task.
The Known Laws: List the 3 most critical invariants discovered.
The Symbol Inventory: A list of every file and major class we are currently working on.
The Open Theory: If we are debugging, state the current Theory of the Bug verbatim.
The Do Not Repeat List: The - most recent failed attempts to avoid looping.
File Attachments Needed: Exactly which source files to attach to the new thread immediately.
Format: “Wrap this in a Markdown code block for easy copying.”
The Handoff Reception (First message in the new thread)
“Navigator, accept this DVCP handoff. [Paste Migration Block here]” [Attach requested source files]
Acknowledge receipt. Do not suggest code yet. Confirm you have correctly parsed the symbols and the theory.”
Appendix D: Case Study—The “Cold Project” Resurrection (Bird Blade)—Deep Cut
DVCP was not forged in a 0-to-1 vibecoding sprint. It was built to solve the cold project problem: returning to a real system months or years later and retaining authority.
In November 2020, I spent 45 days in a focused solo sprint to build the core of Bird Blade. I emerged with 60% of a finished game: multi-bird flight, procedural room generation, and a flight model designed for threading geese-like test subjects through a succession of hazardous corridors, towards a final escape exit 1200 meters away.
When I returned years later, I didn’t want the Navigator to vibe-code a new game. I needed it to help me navigate the original architecture to finish the escape. The first big new feature I vibecoded was support for flock and camera behavior that would smoothly follow a new twisting Catmull-spline in each new procedural chunk. Then I wanted to add an optional “throttle” button for speedrunners.
But let’s hold on the feature where the bird-flock and camera system smoothly follow a spline in a curving procedural chunk of the game, because this was my very first real test of vibe coding, after small successes with some minor one-shot systems.
It did not go smoothly. That’s why DVCP exists today. Bird Blade is a medium-sized project, not one-shottable. It’s full of highly tuned, interconnected systems that ChatGPT 5.2, at first, did not understand (while confidently thinking it did). And I did not understand how to teach it and work through it. It took days of toil, to work through why it kept failing. I almost gave up and called the whole thing off entirely.
But I kept pushing. Pulling back and reasoning about what the model was doing. Killing threads where it got stuck repeating the same bad ideas that it would come up with, that would take a small set of errors and explode them exponentially, breaking multiple source files at once.
Slowly, I was able to recognize the patterns that led to collapse. I started commanding the model strictly to not do things that led to error cascades. I don’t remember a single moment where it clicked. What I remember is stopping—forcing myself and the model to reconstruct the system in plain language, subsystem by subsystem, until the shape of the problem was clear enough to move again.
And one morning, I got it to work. The birds travelled down a spline in a curving level chunk, and kept their formation through the curve.
This felt so good. A spline system is something I would have almost certainly ruled out for this game, because working alone, the amount of time it would take me to learn the math and debug it felt longer than the value-add of the feature alone. That’s what vibe coding can unlock, at its best. You as a human get to delegate the hairy details of a somewhat complex system to an entity that is very good at implementing the engineering arithmetic and its details, as long as the implementation of a lot of similar systems are “known” in its latent space.
Catmull-Rom splines are everywhere in its source code training data. The math is a little tricky for me, but the shape of it all, down to the details, is trivial for these things. Once we got this tough feature fully unlocked, the next 10 features we worked through came lightning fast, one after another, and I was right back in the vibe code honeymoon phase, until it happened again.
The next vibe coding task would be a nuanced feature for speedrunners: the Speed Throttle.
My bird flock’s “Shock and Panic” design, after the player activates the SpeedThrottle, is a perfect DVCP test:
The Surge: The user presses the throttle button, and the lead bird surges forward to clear a closing gap or simply go faster.
The Shock: Trailing birds in the flock experience a moment of genuine shock as the leader leaves them behind. The model wants to optimize for smooth interpolation; the game requires jagged, intentional friction across 3 distinct phases.
The Panic: They transition into a frantic catch-up state and surge forward to re-form the original formation envelope with the leader.
A Navigator left to its own devices would suggest boids for the entire flight model because it “makes sense for birds.” That would erase the hand-coded precision of the original flight authority loop.
This is the exact moment where the Captain’s voice comes back.
No. Scratch that, Navigator. The original 2020 project’s core is law. You’re authorized to touch the boid transition during the ‘shock & panic of the straggler birds’—the SpeedThrottle phase only. The rest is off-limits.
That’s not roleplay. That’s boundary enforcement in a hostile environment—the thing DVCP exists to make reflex. If you can’t pull rank on a plausible-sounding rewrite, you don’t have a protocol. You have a wishlist.
Under DVCP, the Navigator is restricted: it can only touch the new fancy boid transition during the shock & panic state. The 2020 core remains pure; the new 2026 layers respect the established flow.
Appendix E: Adversarial Reads (Resumés, LinkedIn, Decks, and Anything You’re Too Close To)—Deep Cut
One of the most underrated uses of frontier models isn’t generation, it’s cold evaluation.
If you’ve ever sent a resumé into the world and wondered why it didn’t convert, or posted a LinkedIn update and felt the engagement was mysteriously flat, you already know the core problem:
You can’t reliably read your own work or public profile the way a stranger reads it.
You’re inside the story. You know what you meant. You can feel the effort behind a bullet point. A real screen is scanning at speed with zero context and a hair-trigger for vagueness. They are not mean. They are saturated.
This is where adversarial prompting shines.
Why adversarial reads work better than friendly reads:
Most digital assistants are trained to be pleasant. High-empathy phrasing. “Great start!” and “You might consider…”
That’s fine for morale. But if you’re trying to grow, ship, or actually win, that tone can become a distortion field. In real life, nobody gives you the full list of why they passed—they just pass.
So DVCP recommends a specific move:
Use adversarial framing on your own artifacts.
Not to punish yourself, but to compress reality.
When you force a model to behave like a hostile screener, you get:
The dismissal hooks people won’t say out loud. The missing proofs that make claims believable. The cringe triggers that give skeptics permission to ignore you. The rewrite target for the one paragraph quietly ruining the whole thing.
The clean-room method (how to avoid “helpfulness bias”)
If you want the harshest, cleanest read:
Use a logged-out session (Private Browsing is fine). Tell the model: no identity inference. Treat the author as anonymous.
Provide only the text you want judged (resumé, LinkedIn “About,” deck copy, blog section). Forbid browsing. Forbid guessing. Demand quotes.
You’re not asking the model to be cruel. You’re asking it to simulate the reality that already exists: fast rejection in a noisy world.
This applies far beyond resumés:
Hiring loops (resumé, portfolio, writing sample). Fundraising (deck, memo, positioning). Product pages (home page, onboarding copy). Big posts (your vibe coding guide that you’re emotionally attached to).
If it stings, good. That sting is usually a real weak point getting exposed before a real person sees it.
A safety note (non-negotiable)
Use these prompts only on text you provide.
Do not include secrets, credentials, private identifiers, or third-party personal data.
This is red-teaming your own writing, not investigating people.
Copy-paste templates: High-stakes Adversarial Prompts
These are designed to produce the kind of blunt read you’d get from someone with real stakes (a hiring committee, an investment committee, or an internet scanner looking for one excuse to dismiss you.)
Hiring Committee Sniper (Resumé / LinkedIn / Portfolio)
You are a senior hiring committee member screening 200 candidates. You are tired and suspicious.
Constraints:
Anonymous candidate. Do not infer identity, employer, location, demographics, or intent. Use ONLY the pasted text. No web browsing. No guesses. No benefit-of-the-doubt. No coaching tone. No encouragement. No empathy. Prefer “not enough signal” over speculation.
Output:
Verdict: NO / MAYBE / YES (default NO). 8 reasons you’d reject in 30 seconds (each tied to a quote). 5 signals that look inflated, vague, or unverifiable (quote them). 5 missing specifics that would have moved you to MAYBE. Rewrite the top section into the version that gets a MAYBE from you in 15 seconds. One sentence: “What kind of candidate is this?” (harsh but fair).
TEXT:
[PASTE RESUME/LINKEDIN/PORTFOLIO CONTENT HERE]
Blind Kill-Switch (General-purpose rejection engine)
SYSTEM / ROLE: You are a hostile screening committee. Your job is not to help. Your job is to reject quickly and defensibly.
CONSTRAINTS:
Treat the author as anonymous. Do not infer identity or intent. Use ONLY the pasted text. No web browsing. No guesses. No benefit-of-the-doubt. Assume 500 competing submissions. You have 90 seconds. You must produce reasons to say “no” that would survive scrutiny in a real committee.
TASK:
Give a binary verdict: REJECT or ADVANCE. Default to REJECT unless the text forces ADVANCE.
List the top 10 “dismissal hooks” (phrases/claims that trigger skepticism or eyerolls).
List the top 5 “missing proofs” (the exact evidence required to believe the claims).
Identify 3 places the text tries to manage your feelings or narrate around lack of proof. Quote them.
Rewrite only the weakest paragraph into a version that survives a hostile reader. Keep it short. No hype.
TEXT:
[PASTE TEXT TO BE SCREENED HERE]
Investment Committee Red Team (Deck / Product positioning)
You are writing the INTERNAL IC MEMO that argues against doing this deal. You are rewarded for finding fatal flaws.
Rules:
Anonymous author. No identity inference. Use ONLY the provided text. No browsing. Assume the founder is charismatic; resist charisma and focus on falsifiable reality.
Deliverables:
A) 1-paragraph “Why this fails” thesis.
B) 12 bullets: “Reasons to pass” (specific, not vibes).
C) 6 bullets: “Questions that, if unanswered, are deal-killers.”
D) 5 bullets: “Evidence required” (metrics, retention, contracts, technical proofs).
E) 3 bullets: “If we funded anyway, what exact bet are we making and why is it still stupid?”
F) Rewrite the positioning into one falsifiable sentence.
TEXT:
[PASTE DECK COPY/POSITIONING HERE]
The “Autist Scanner” Weak-Point Hunter (Blog post / vibe coding guide)
You are a hostile internet reader with high pattern sensitivity. Your goal is to find weak points, cringe, contradictions, and anything that lets you dismiss the whole piece.
(“Autist scanner” here is internet shorthand used with respect: high-IQ, pattern-sensitive, detail-oriented reading—precision scrutiny, not a slur.)
Rules:
Use ONLY the pasted text. No identity inference. No browsing. Do not be polite. Do not offer balance unless forced by the text.
Quote the exact phrases you are attacking.
Deliver:
The 7 weakest lines (quote + why it fails).
The 5 “cringe triggers” (roleplay, grandiosity, needless jargon, faux-rigor).
The 5 most attackable claims that need evidence (and what evidence).
The 3 strongest lines (reluctantly admit them).
A rewrite plan: cut list (delete), tighten list (compress), clarify list (make concrete).
TEXT:
[PASTE ESSAY/POST CONTENT HERE]
A final note on why this belongs in the Doomlaser Vibe Coding Protocol
DVCP is a governance system. Governance isn’t just about preventing broken code. It’s about preventing self-deception.
If you can’t get a cold read on your own resumé, your own deck, your own post, or your own plan, you’re navigating by dead reckoning: hoping your internal story matches the outside world.
Adversarial reads are a cheap, repeatable “visual fix.” Use them.
They will hurt your feelings. That is the point.
The Point: The Doomlaser Vibe Coding Protocol isn’t about doing less work. It’s about doing higher-level work without losing the ship. If you’re currently navigating by dead reckoning:
Stop. Initiate Map Mode. Find the stars again.
Appendix F: Why being polite and courteous to your LLM is NOT superstition, after all—Deep Cut
When LLMs were new, it was very common to see people who would feel self-conscious when this observation about their own behavior dawned on them: that in their very own missives to these ‘systems,’ they were often writing in an excessively polite and friendly tone.
LLMs are machines, after all, not actually other humans. No real “feelings” could be hurt on the side of the machine. Sometimes, certain widely publicized “LLM oneshot jailbreak” prompts would perform even better than ordinary conversation, and often when those very viral prompts were excessively hostile, or contained outright lies and deceptions.
I remember a moment on the All-In Podcast when David Sacks (now the US federal government’s AI Czar) briefly showed his ChatGPT scrollback. The other ‘bestie’ hosts immediately teased him for how polite and obsequious his prompts were.
The implication was obvious: this kind of courtesy was a human psychological glitch, an embarrassing carryover from talking to real people. The ribbings landed because, by then, it had become accepted online wisdom that politeness toward an LLM was irrational; a superstition arising from humans conversing with a machine through a human-shaped interface.
This was not a rare occurrence or a meme.
It became accepted general knowledge online that this kind of behavior was a fault of human psychology. It was just another superstition borne out from “conversing” with an artificial pattern recognizer through a chat interface, a place that had hitherto been the exclusive domain of real living human beings.
I’m here now to tell you that, no, being polite with your chosen LLM is not a superstition. And the reason why should be obvious.
LLMs are artificial pattern recognizers. They don’t have traditional embodied feelings like humans do, at all. They’re stochastic machine algorithms.
All they do is take your input text and predict, through cold hard linear algebra, a set of tokens that completes and extends the pattern that they identify in a text prompt, running that through a static and unchanging “latent space,” which itself is a mechanistic compression of their almost incomprehensibly vast amounts of training data, consisting only of a very large amount of simple plain text. That’s it.
Your prompt is fed into the machine with an attached integer variable representing the number of “tokens” to predict, and a “temperature” variable which represents how loose the model can be in its statistical free-association while assembling its reply.
But that’s the whole point. They’re using your prompt as a template for how to reply.
The mathematical mechanics of how to extend that template of characters is not what makes it special.
And this is something that critics of LLMs seem to often forget.
Yes, it’s true. It’s just math. It’s not magic.
But the part that makes LLMs feel special isn’t the completion algorithm, it’s the latent space itself.
LLMs are like a statistical hermit crab wearing a shell of the collective output of every human who has ever lived. Human language alone is inseparable from the human biological evolution it arose under.
It emerged from embodied biological brains, and evolved over the course of more than a billion years of life on Earth.
Language is the coordination layer devised by individual humans to accomplish goals together, collectively. Whether it’s building controlled fires, hunting for protein, or a simple call and response between a mother and her child: to make sure that it is okay, to reassure it when it stumbles, to scold it when it does something dangerous.
The magic is that this latent space, assembled algorithmically, represents every effective piece of human communication that has ever been written. And the “shape” of this mathematical manifold, now likely approaching a network of over a trillion highly multidimensional interlinked and weighted vectors, and that your prompts then filter through probabilistically, is itself the remains of a collective biological husk.
And you can’t separate that ‘latent space’ from the long, brutal process of natural selection, conducted by living human individuals and their lineage, over the course of that billion years.
The “ghost” in the LLM you are talking to is the ghost of human coordination itself. That’s why it feels like magic.
And, to put it simply, while the machine is probabilistically extending a static pattern of N new tokens to tack onto the end of a static block of text, the fact remains that the entire reason humans are polite in the first place is to better organize coordination between them.
If you are polite and thankful in your prompts, the LLM will extend that pattern with its own pattern of politeness and helpfulness in the replies it writes back. There’s nothing magic about that.
As your set of generated tokens grows, in a long and complex chat thread, the politeness and helpfulness will reinforce itself and feed back organically, algorithmically.
So no, there’s nothing superstitious about it. It’s just effective
communication, now between man and machine. Just as politeness itself
represents the evolved and effective coordination between individual
humans and the larger human collective.
And if you’d like to end with something practical, that I regularly use
in my own prompts to LLMs: require your models include a few unicode emojis in
their replies. Tell your model, explicitly, to include 1-2 emojis in
each reply, that creatively represents the implied internal state of the
model at the moment it is drafting a completion, and how it ‘feels’
about the current ‘vibe’ of the user, and itself.
🤖🤵🪄
Appendix G: On American vs. Chinese AI Innovation, and Why “Local” is the New Battlefield
For most of the last decade, it was taken as gospel that US frontier labs were meaningfully ahead of everyone else and were effectively unbeatable.
They had more data, more compute, better talent, better institutions, and more capital to maintain the flywheel of superiority. I believed this too, for a long time. After actually using the recent Chinese models—specifically Qwen—I believe that this is no longer a defensible position.
Direct interaction with recent Chinese models invalidates the assumption that US frontier labs retain a clear technical lead. The Chinese labs are innovating along dimensions that the US has largely abandoned: efficiency, controllability, interaction quality, and architectural clarity.
Qwen does something deceptively simple and profoundly important: it separates thinking from answering. There is an explicit long reasoning pass, followed by a clean response pass. The result is not just better answers, but a better interaction. It is easily legible. And it feels like a tool, not a therapist or a mascot.
They also deploy a Mixture-of-Experts architecture that delivers roughly 30B-class capability while activating only ~3B parameters at a time, meaning it can run on a consumer-grade laptop, or a beefy smartphone. That is real innovation, not another scaling stunt. This is a direct attack on the cost, latency, and energy assumptions that now dominate American frontier strategy.
By contrast, the dominant US pattern over the last two years has been comparably simplistic: more parameters, more data (now even rationalizing training with synthetic data), more capital, and a constant push for more platform gravity. Spend hundreds of billions, maybe trillions, and call it progress. The meta seems to be GPT-1 but just way bigger. This is not obviously wrong—but it is no longer obviously winning.
OpenAI as a Case Study in Institutional Decay (?)
OpenAI matters here because it represents the clearest example of how institutional incentives shape technical outcomes.
OpenAI was founded as a nonprofit, explicitly framed around benefiting humanity. That governance structure mattered. It constrained behavior. It shaped product decisions. It signaled that something other than pure profit maximization was in play.
That is no longer the case.
OpenAI is now a for-profit entity with effectively unlimited capital pressure and a single dominant product: ChatGPT. Everything else flows from that fact. The API, its hyperspeed model churn, and OpenAI now forcing chat-first design, through the total removal of pure completion models (RIP: text-davinci-003), are not accidents or missteps.
They are rational outcomes of a platform-capture strategy.
From a builder’s perspective, the OpenAI API is now structurally hostile to durable application development. Models are deprecated before serious projects can mature. Completion-level control has been totally removed from its API endpoints in favor of chat-shaped interfaces, exclusively. The result is that every developer is architecturally pushed toward building a worse version of ChatGPT, something OpenAI will always do better itself.
This harms all API users, not just independents and medium-sized businesses. Institutions with large budgets are not protected; they are simply slower to notice. Their data flows through OpenAI anyway. Their products remain dependent. OpenAI likely trains on their API-processed data. Their leverage decreases over time.
This is about incentives. I’m not making a morality claim. And given its current incentives, OpenAI has diminishing structural reasons to optimize for third-party system sovereignty. In practice, the API’s design and churn increasingly prioritize revenue capture and platform gravity over long-lived third-party systems.
From OpenAI’s perspective, they are probably not that worried about the Qwen models yet. ChatGPT 5.2 is larger, more versatile, and has hundreds of millions of real users who rely on it every week—almost a billion even. I count myself among them! It’s a good product, mostly. But I see the local Qwen models as something akin to an Innovator’s Dilemma situation for OpenAI.
Sure, they may see them as toy models by comparison today, but just like IBM was somewhat unworried about the toy-like personal computing industry of the 1970s, especially in comparison to their own beefy & professional System/370 mainframe and System/7 minicomputers of the time, these personal computer toys like the Apple II and Commodore 64 eventually became powerful enough for users to accomplish real work that would have been otherwise captured by IBM.
The same may be true for OpenAI and its ChatGPT dominance as Qwen improves.
Why Local and Developer-Controlled Models Are the Future
Against this backdrop, the renewed relevance of local AI and developer-controlled models is really about basic builder practicality.
If you care about:
-
durability
-
completion semantics
-
architectural control
-
predictable costs
-
resistance to platform sabotage
then you must either own the model outright or deploy against a version-pinned, contractually stable model whose weights, interface, and behavior cannot be altered unilaterally by a platform provider. Full stop.
Chinese labs, whether intentionally or not, are serving the builder class better right now. Their models are easier to reason about, easier to integrate, free, and less encumbered by platform theater.
They feel like components. Whereas the leading American AI API offers products pretending to be friends.
For developers, this all reduces down to one question: can you build something durable on top of the thing or not?
The Larger Point.
I’m not arguing “China good, America bad” here. Far from that. I’m pointing out something narrower and more uncomfortable:
America is no longer clearly innovating where it matters most.
The US still leads by far in capital intensity and deployment scale. China is increasingly leading in efficiency, interaction design, and architectural insight. These are things to be worried about. They are the dimensions that determine whether American AI becomes infrastructure or a cold enclosure.
OpenAI did not lose its mission by accident. It lost it because the mission was incompatible with the incentives it chose. That choice, to pursue a 100% profit-maximizing outcome, and to protect its moat through platform lock-in, now colors everything it does.
Builders who want long-lived systems should plan accordingly.
We are at the end of the ‘Magic’ era of AI. The frontier labs are currently trapped in a scaling war, churning out massive, polite assistants that are increasingly incompatible with the precision of real-world engineering. They are optimizing for the ‘chat,’ while we are building for the ‘vibe.’
If the American frontier wants to remain relevant to the builder class, it must stop trying to be our ‘friend’ and start being our ‘component’. It must offer us the weights, the logic, and the structural integrity we had with Davinci-003—for a fair price—or it must accept its fate as a provider of expensive, high-latency slop.
The choice for the developer is simpler: you can remain a tenant in a ‘Cold Enclosure’, or you can throw on that Mariner’s Cap, run your own engine locally or by other means, and learn to read the stars again. This DVCP is the bridge. Don’t get lost out there.
If you’d like to read more, you can find the author on X / Twitter at @Doomlaser.