Doomlaser Interview on AI, Scaling Limits, and Governance (from 2015)
I dug up a 1-hour public radio interview I did in 2015 for Dave Monk’s WEFT 90.1 FM show, where I describe AI as “high-level algebra” used to make sense of abstract inputs—which is basically what modern LLMs are: tokenized text turned into vectors, pushed through huge stacks of matrix multiplications, producing a next-token distribution.
What makes the interview interesting in hindsight isn’t the prediction; it’s that certain constraints were already visible once intelligence is treated as math plus incentives, rather than as something mystical.
Back then, I didn’t have the words “Transformer” or “latent space”, but the core intuition was the same: intelligence-as-inference, not magic.
The interview was recorded months before OpenAI was founded, during a period when “AI” mostly meant expert systems, narrow ML, or sci-fi abstractions. We ended up talking about things that feel oddly current now:
• Why “reasoning” might not simply emerge from brute force
• Automation, labor displacement, and second-order effects
• Speculative governance models for advanced AI
• The idea of for-profit engines constrained or controlled by nonprofit oversight
At the time, these were armchair frameworks—attempts to reason from first principles about where computation, incentives, and institutions tend to drift when scaled.
Listening back now, I’m struck by how much of the underlying structure was visible at a time when many second-order effects were still difficult to imagine.
Why resurface this now?
I initially revisited the recording after recent public comments from Sergey Brin about Google’s under-investment in AI research and architectural bets. There’s a familiar pattern here: long stretches of incremental progress, followed by abrupt nonlinear jumps once the right abstraction and enough compute collide.
Transformers didn’t make intelligence appear out of nowhere. They provided a usable way to stack inference at scale.
In that sense, LLMs feel less like a revolution and more like a delayed convergence—linear algebra finally getting enough data, enough depth, and enough money to show its teeth.
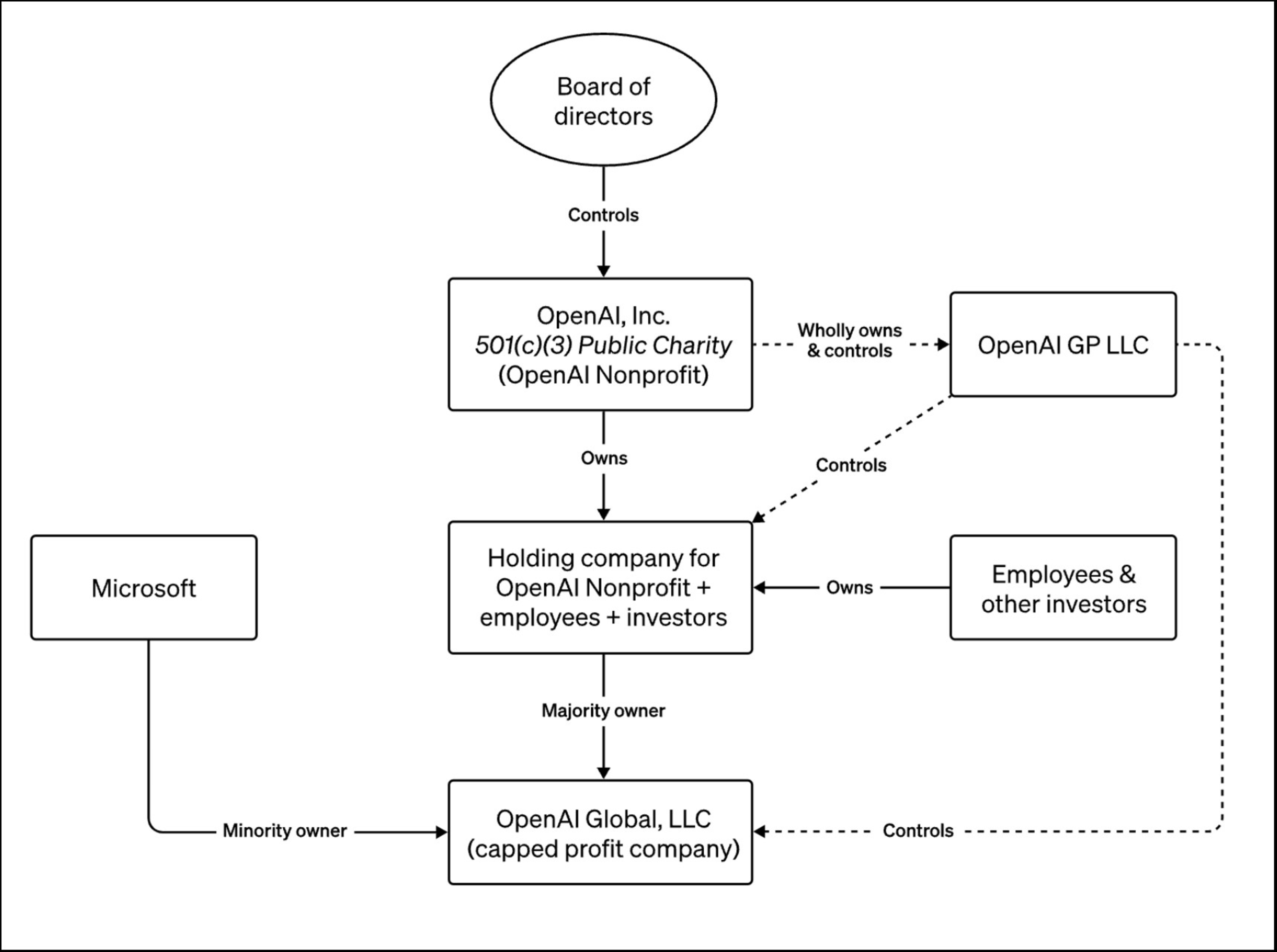
Governance, incentives, and structure
One part of the interview that surprised me is how much time we spent on corporate governance and institutional design. In particular, we discussed a model where:
• But is structurally constrained by a nonprofit or mission-locked entity
• To limit runaway incentive capture
That general shape later materialized, imperfectly and contentiously, in OpenAI’s original structure.
I think many people were circling similar ideas at the time. It’s more interesting as an example of how certain governance configurations are almost forced once the underlying economics become obvious.
The full conversation is up on YouTube. It’s long, covers a lot of ground, and is very much a product of its era, but I think it holds up as an archival artifact of how some of these ideas were already forming before the current wave.
I’m curious which parts people think aged well, and which feel naive or clearly wrong in a post-LLM world. That delta is often more interesting than the hits.
Here is a full text transcript of that 2015 conversation on public radio, if you’d like to read it directly.

January 23rd, 2026 at 12:32 am
[…] constrained by nonprofit oversight: Recorded months before OpenAI was founded, the conversation treats intelligence as math plus incentives rather than something mystical, touching on architectural bottlenecks, why “reasoning” may not […]
December 24th, 2025 at 5:12 am
[…] sin fines de ganancia: Grabada meses ayer de que se fundara OpenAI, la conversación negociación la inteligencia como matemáticas más incentivos en emplazamiento de poco piadosotocando los cuellos de botella arquitectónicos, explica por qué el “razonamiento” no […]
December 24th, 2025 at 4:56 am
[…] constrained by nonprofit oversight: Recorded months before OpenAI was founded, the conversation treats intelligence as math plus incentives rather than something mystical, touching on architectural bottlenecks, why “reasoning” may not […]
December 23rd, 2025 at 5:20 pm
[…] 详情参考 […]